Comparing Static Analyses for Improved Semantic Conflict Detection
Abstract
Version control systems are essential in software development, allowing teams to collaborate simultaneously without interfering with each other's work. Tools like Git facilitate code integration through merge operations, which automatically resolve textual conflicts. However, these systems focus solely on source code differences, overlooking more complex semantic conflicts that can lead to failures or unexpected behavior after integration. To address this challenge, static analysis emerges as an effective solution, detecting semantic conflicts that traditional merge tools might miss, providing an additional layer of security and quality to the code integration process. Our study combines different static analysis techniques to enhance the effectiveness of detecting semantic conflicts, tested across 32 real-world projects from GitHub. Depending on the context, some analyses prove more suitable than others: in areas where precision is crucial, such as medical or financial systems, techniques that minimize false positives are prioritized; while in security or monitoring projects, techniques with higher recall are preferred to ensure that as many issues as possible are identified, even if it results in some false alarms. The results show that combining static analysis strategies delivers superior performance in terms of precision, recall, F1 score, and accuracy compared to previous methods, and is a more lightweight and flexible approach to adapt to the application context.
Authors
- Galileu Santos de Jesus (gsj@cin.ufpe.br)
- Paulo Borba (phmb@cin.ufpe.br)
- Rodrigo Bonifácio (rbonifacio@unb.br)
- Matheus Barbosa de Oliveira (mbo2@cin.ufpe.br)
Comparing Static Analyses for Improved Semantic Conflict Detection
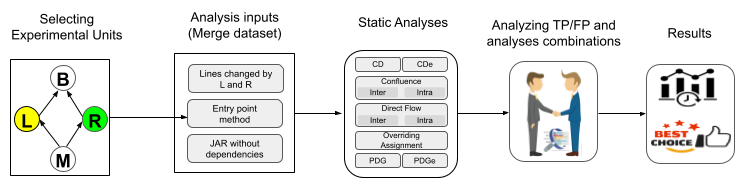
To detect interference and help mitigate the negative consequences of semantic conflicts, we propose a technique that runs static analyses on the merged version of the code, which we annotate with metadata indicating instructions modified or added by each developer. In particular, by running a static control dependence analysis on the example illustrated in the previous section, a tool could report that a method invoke instruction added by Right is control dependent on a conditional instruction modified by Left, warning about the existing interference.
We compare the interference ground truth with the combinations generated from the analysis results and compute precision, recall, F1 score, and accuracy metrics. When combining the nine approaches, we explore over 500 distinct possible configurations, performing the combination one by one and applying the logical OR operation for each set of approaches, resulting in a single outcome for each specific combination. Next, we calculate the metrics for each of these combinations. Additionally, we evaluate if the most effective combinations are subsets of other configurations with the same outcome. If so, we eliminate the larger configurations, retaining only the smaller and therefore more efficient ones. This procedure enables us to achieve the same result in less time.
To assess the contribution of each static analysis technique, we used the Exclusive True Positives (TPe) and Exclusive False Positives (FPe) metric. This metric was developed to measure the effectiveness of each analysis in isolation, highlighting its specific contributions in terms of true positives (TP) and false positives (FP). The TPe represents the number of true positives identified exclusively by a given analysis, while the FPe corresponds to the false positives attributed exclusively to that analysis. The difference between TPe and FPe provides a balanced measure that highlights the net impact of each analysis. The higher the TPe-FPe value, the greater the contribution of the analysis in providing accurate results without generating excessive noise, making it essential for evaluating the precision and usefulness of static analysis techniques in detecting semantic conflicts.
Sample
Here you can find the list of projects of our sample. For each project, we present some metrics collected from GitHub or locally by git.
Here, you can find the list of changes on the same declarations we analyzed in our study. Each change is represented as a row in the table below.
Study Replication
Here you can find the links for the scripts and dataset we used to perform our study. Aiming to support replications, we provide our sample of merge scenarios as a dataset.
Below, we present in detail how our scripts can be used to replicate our study using our dataset.
Replicating the study
We recommend the execution of the next steps when trying to replicate our study. In order to facilitate the replication of our study, we created a docker container that assembles all the necessary infrastructure for the complete execution. To use it, you need to have docker installed on your machine, so follow the instructions in the official documentation: https://docs.docker.com/desktop/install. After installation or if you already have docker installed, we have prepared a guide so you can create an image, initialize a container and run the analyses.