Detecting Semantic Conflicts with Unit Tests
Abstract
Branching and merging are common practices in collaborative software development. They increase developer productivity by fostering teamwork, allowing developers to independently contribute to a software project. Despite such benefits, these practices come at a cost--- the need to merge software and resolve merge conflicts, which often occur in practice. While modern merge techniques, such as 3-way and structured merge, can resolve textual conflicts automatically, they fail when the conflict arises not at the syntactic but at the semantic level. Detecting such semantic conflicts requires understanding the behavior of the software, which is beyond the capabilities of most existing merge tools. Although semantic merge tools have been proposed, they are usually based on heavyweight static analyses, or need explicit specifications of program behavior. In this work, we take a different route and propose SAM (SemAntic Merge), a semantic merge tool based on the automated generation of unit tests that are used as partial specifications of the changes to be merged, and drive the detection of unwanted behavior changes (conflicts) when merging software. To evaluate SAM’s feasibility for detecting conflicts, we perform an empirical study relying on a dataset of more than 80 pairs of changes integrated to common class elements (constructors, methods, and fields) from 51 merge scenarios. We also assess how the four unit-test generation tools used by SAM individually contribute to conflict identification: EvoSuite (the standard and the differential version), Randoop, and Randoop Clean, an extended version of Randoop proposed here. Additionally, we propose and assess the adoption of Testability Transformations, which are changes directly applied to the code under analysis aiming to increase its testability during test suite generation, and Serialization, which aims to support unit-test tools to generate tests that manipulate complex objects. Our results show that SAM best performs when combining only the tests generated by Differential EvoSuite and EvoSuite, and using the proposed Testability Transformations (nine detected conflicts out of 28). These results reinforce previous findings about the potential of using test-case generation to detect test conflicts as a method that is versatile and requires only limited deployment effort in practice.
Authors
- Léuson Da Silva (lmps2@cin.ufpe.br)
- Paulo Borba (phmb@cin.ufpe.br)
- Toni Maciel (jaam@cin.ufpe.br)
- Wardah Mahmood (wardah@chalmers.se)
- Thorsten Berger (thorsten.berger@rub.de)
- João Moisakis (jprm@cin.ufpe.br)
- Aldiberg Gomes (agcj2@cin.ufpe.br)
- Vinicius Leite (vtls@cin.ufpe.br)
SAM: SemAntic Merge tool based on Unit Test Generation
The essence of SAM is to generate and execute tests when merge scenarios are performed. These tests are executed over the different commits of a merge scenario, and after interpreting their results, the tools report whether a semantic conflict is detected.
SAM receives as input a merge scenario and, based on the changes performed by developers, invokes unit test generation tools to generate test suites exploring the ongoing changes. Next, based on some heuristics, SAM checks whether test conflicts occur by comparing the test suites’ results against the different merge scenario commits. If a conflict is detected, the tool warns developers about its occurrence, informing the class and its element involved in the conflict. Figure 1 below shows how SAM works. Our current version of SAM is available on GitHub.
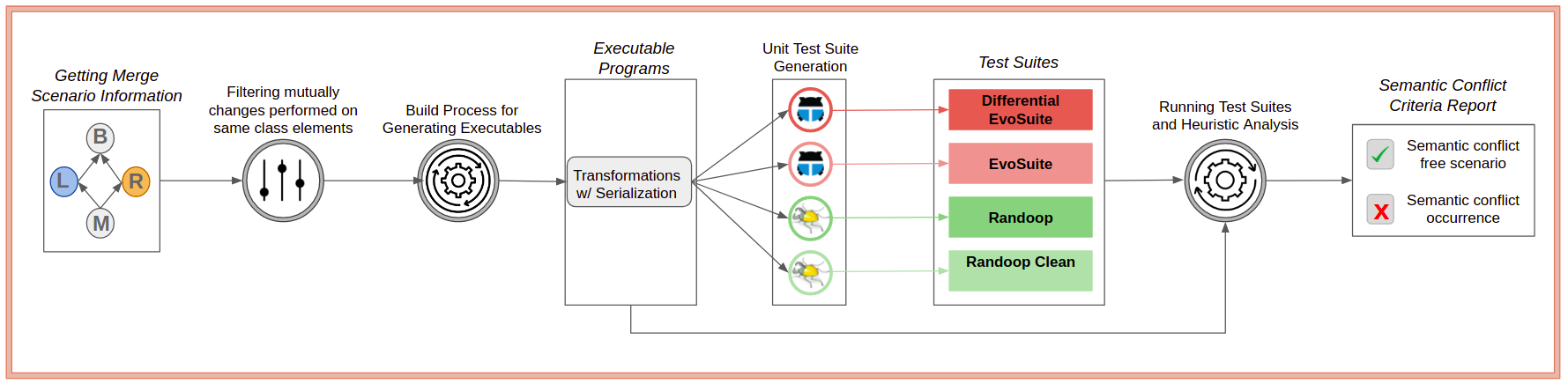
Using Regression Testing for detecting semantic conflicts
We present here our dataset of 85 mutually integrated changes’ pairs on class elements (constructors, methods, and fields) from 51 software merge scenarios mined from 31 different projects. In 28 changes, we can observe the occurrence of semantic conflicts (column Semantic Conflict). Using Regression Testing, we were able to automatically detect 9 of these conflicts. Figure 2 below shows the steps we adopt in this study.
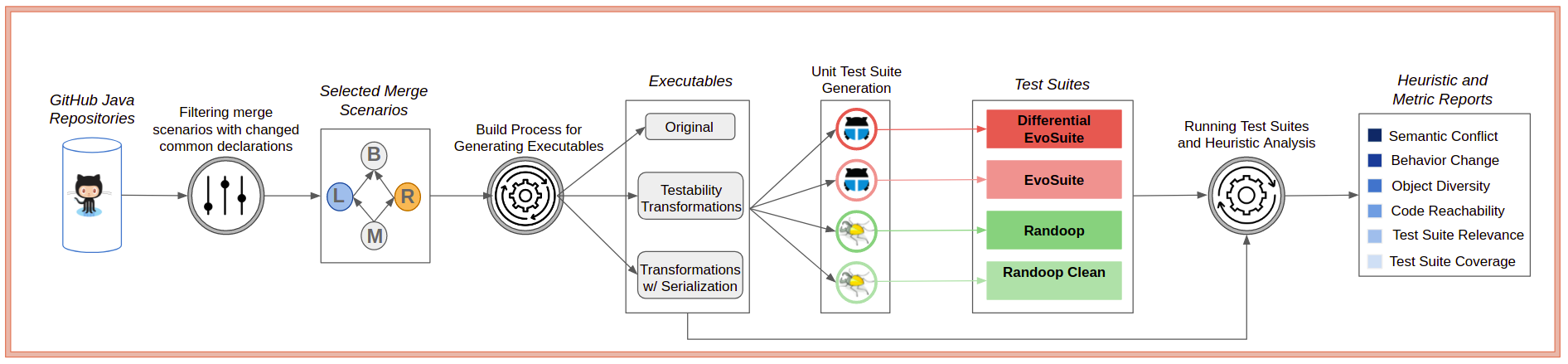
Here, you can find the list of changes on the same declarations we analyzed in our study. Each change is represented as a row in the table below.
- In the column Target Class, we report the class where the parent commits apply simultaneously their changes. Additionally, we provide a link for the project commit associated with that merge scenario.
- In the column Changed Element, we report the element simultaneously changed by the parent commits. That element might be an attribute, a method, or a constructor.
- In the column Semantic Conflict, we report whether the change represents a semantic conflict based on our notion of local interference (manual analysis).
- In the column Detected Conflict, we report whether the semantic conflict was detected by our study using regression testing.
- In the columns Left and Right Orig., Trans., and Seria., you can find the generated test suites for the original, transformed, and serialized versions, respectively, from each merge scenario.
For the HikariConfig case, a semantic conflict occurs based on our ground truth. During our study, SAM reported a conflict for this case; however, the reported test was flaky. As a result, we consider this case as a false-positive. For further discussion about FPs, please, check our paper.
For additional details regarding our dataset, you can find further information here. We provide descriptions for each row of the table above, like whether the associated changes represent a conflict, the summary of changes performed by each parent commit, and when applicable, also a test case revealing the conflict.
For additional details regarding the set of test cases that detected semantic conflicts, please check this file. We inform the test cases of each test suite that detected any of the semantic conflicts.
As a final remark, regarding the general behavior changes detected in our study, please check this file.
Study Replication
Here you can find the links for the scripts and dataset we used to perform our study. Aiming to support replications, we provide our sample of merge scenarios as a dataset. This dataset is composed of build files required for our scripts for the generation of test suites by the unit test generation tools, and execution of these suites against the different versions of a merge scenario.
Below, we present in detail how our scripts can be used to replicate our study using our dataset or perform a new one using another sample.
Replicating the study
We recommend the execution of the next steps when trying to replicate our study.
- Getting the build files - We provide the sample of our study as a dataset with the jar files for the original and transformed versions for each merge scenario commit. So, you must clone the Github project and run the script get_sample.py. As a result, the file results_semantic_study.csv will be created, required as input for the next step.
- Setting up the scripts - After having the local dataset available, you must clone the project with our scripts, which generate and execute test suites using unit test generation tools. After cloning, you must rename the configuration file env-config.template.json for env-config.json. Next, you must inform the path of the file generated in the last step on path_hash_csv. Additional information to setup other options is given in the Github project page.
- Running the study - Our scripts require Python 3.6.x. In case you are running on a Linux terminal, you can just call the semantic_study.py . As a result, the file semantic_conflict_results.csv and the folder output-test-dest grouping the generated test suites will be created .
- Tools Versions - To run this study, we consider four different unit test tools. Regarding EvoSuite and Differential EvoSuite, these tools are provided by the same jar file; this way, we adopted version 1.0.6. Regarding Randoop, we adopted version 4.2.5. Finally, regarding Randoop Clean, as our modified version was developed based on the latest version of Randoop, we also consider version 4.2.5.
Running a new study
- Building Merge Scenarios - For our study, we used the MiningFramework to automatically create the build files associated with each merge scenario commits on Travis. For a new sample, you can inform a list of projects, and MiningFramework will use Travis to generate the jar files associated with the original and transformed versions for each merge scenario. In the project page of MiningFramework, you can find additional information about how this framework works.
- Testability Transformations - For each merge scenario evaluated in our study, we consider a original transformed executable version for each commit. These transformations are performed using a jar file that we implemented. Mining Framework already applies these transformations, so you do not need to call it for each commit. In case you want to apply the transformations manually, you can find visit our project on GitHub and look for instructions/guidelines on how to apply them.
- Serialization - Based on our previous findings, we observe that unit test tools face some problems when generating complex objects (external and multiple dependencies). In order to address this issue, we propose feeding the tools with serialized executable versions. For that, we present OSean.EX , our serializer tool available on GitHub. OSean.Ex receives as input a list of commits, and, based on a specific target method, the tool runs the original project test suite to create serialized objects. These objects are saved and used when generating executable jars for all commits previously informed.
- Running the study - After generating the jar files using the MiningFramework, it will create a local file results_semantic_study.csv with the information for each merge scenario mined by the framework. This file must be given as input for the scripts to generate and execute test suites. From this point, you must follow the previous steps when presenting Replicating the study starting on step 2.